
Google เปิดเผยผลการประเมินความแม่นยำของ AI Chatbot ผ่าน FACTS Benchmark Suite พบว่าโมเดลที่ดีที่สุดยังให้คำตอบถูกต้องไม่ถึง 70% สะท้อนความเสี่ยงของการใช้งาน AI เป็นแหล่งข้อมูลโดยไม่ตรวจสอบ
Google เผยแพร่รายงานการประเมินความแม่นยำของ AI Chatbot อย่างตรงไปตรงมา ผ่านชุดทดสอบใหม่ที่ชื่อว่า FACTS Benchmark Suite โดยผลลัพธ์ชี้ชัดว่า แม้แต่โมเดล AI ชั้นนำในปัจจุบัน ก็ยังไม่สามารถให้ข้อมูลที่ถูกต้องได้อย่างน่าเชื่อถือในทุกสถานการณ์
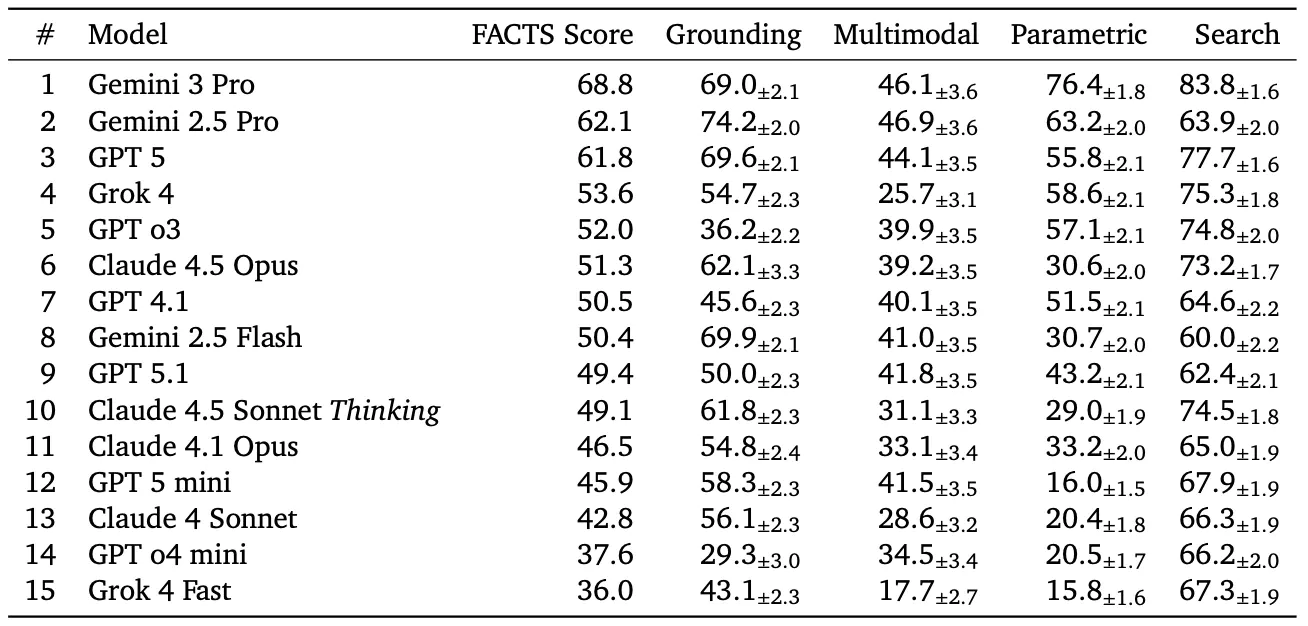
จากผลการทดสอบ โมเดลที่ทำคะแนนสูงสุดคือ Gemini 3 Pro ของ Google ซึ่งมีความแม่นยำด้านข้อเท็จจริงอยู่ที่ 69% หมายความว่าโดยเฉลี่ยแล้ว AI ยังตอบผิดประมาณ 1 ใน 3 คำถาม ขณะที่โมเดลอื่นจากค่ายใหญ่ก็ทำคะแนนได้ต่ำกว่า ไม่ว่าจะเป็น OpenAI, Anthropic หรือ xAI
Google ระบุว่า ปัญหาหลักของการประเมิน AI ในอดีต คือการโฟกัสว่า “ทำงานได้หรือไม่” มากกว่าการตรวจสอบว่า “ข้อมูลที่ตอบนั้นถูกต้องหรือไม่” ซึ่งเป็นช่องโหว่สำคัญ โดยเฉพาะในอุตสาหกรรมที่อ่อนไหวอย่าง การแพทย์ การเงิน และกฎหมาย เพราะคำตอบที่ดูมั่นใจแต่ผิดพลาด อาจสร้างความเสียหายได้จริง
FACTS Benchmark Suite ถูกออกแบบมาเพื่อทดสอบความถูกต้องในบริบทการใช้งานจริง แบ่งออกเป็น 4 ด้านหลัก ได้แก่
-
Parametric Knowledge ความรู้เชิงข้อเท็จจริงจากข้อมูลที่เรียนรู้มา
-
Search Accuracy ความสามารถในการค้นและอ้างอิงข้อมูลจากเว็บ
-
Grounding การยึดข้อมูลจากเอกสารต้นทางโดยไม่แต่งเติม
-
Multimodal Understanding การอ่านและตีความกราฟ ตาราง และภาพ
ผลที่น่ากังวลคือ การทดสอบแบบ Multimodal เป็นจุดอ่อนของ AI แทบทุกค่าย โดยความแม่นยำส่วนใหญ่อยู่ต่ำกว่า 50% ซึ่งหมายความว่า AI อาจ “อ่านกราฟผิด” หรือ “ดึงตัวเลขจากเอกสารผิด” ได้โดยที่ผู้ใช้ไม่ทันสังเกต
บทสรุปจาก Google ไม่ได้บอกว่า AI Chatbot ใช้งานไม่ได้ แต่ย้ำชัดว่า การเชื่อ AI แบบไม่ตรวจสอบยังมีความเสี่ยงสูง และในระยะนี้ AI ยังต้องพึ่งพาโครงสร้างการตรวจสอบ การกำกับดูแล และมนุษย์ควบคุม ก่อนจะสามารถใช้เป็นแหล่งความจริงได้อย่างแท้จริง





